












다양한 데이터 유형 처리#
이 장에서는 n8n core nodes를 사용하여 다양한 유형의 데이터를 처리하는 방법을 배우게 됩니다.
HTML 및 XML 데이터#
HTML 및 XML에 익숙할 것입니다.
HTML vs. XML
HTML은 웹 페이지의 구조와 의미를 설명하는 데 사용되는 마크업 언어입니다. XML은 HTML과 유사하지만 태그 이름이 다르며 보유하는 데이터의 종류를 설명합니다.
n8n 워크플로우에서 HTML 또는 XML 데이터를 처리하려면 HTML node 또는 XML node를 사용하세요.
HTML node를 사용하여 CSS 선택기를 참조하여 웹 페이지의 HTML 콘텐츠를 추출합니다. 이는 웹사이트에서 구조화된 정보를 수집하려는 경우 유용합니다(웹 스크래핑).
HTML 연습#
최신 n8n 블로그 게시물의 제목을 가져봅시다:
- HTTP Request node를 사용하여 URL
https://blog.n8n.io/에 GET 요청을 만듭니다(이 엔드포인트는 인증이 필요하지 않습니다). - HTML node를 연결하고 페이지에서 첫 번째 블로그 게시물의 제목을 추출하도록 구성합니다.
- 힌트: CSS 선택기 또는 HTML 읽기에 익숙하지 않은 경우, CSS 선택기
.item-title a가 도움이 될 것입니다!
- 힌트: CSS 선택기 또는 HTML 읽기에 익숙하지 않은 경우, CSS 선택기
해결책을 보여주세요
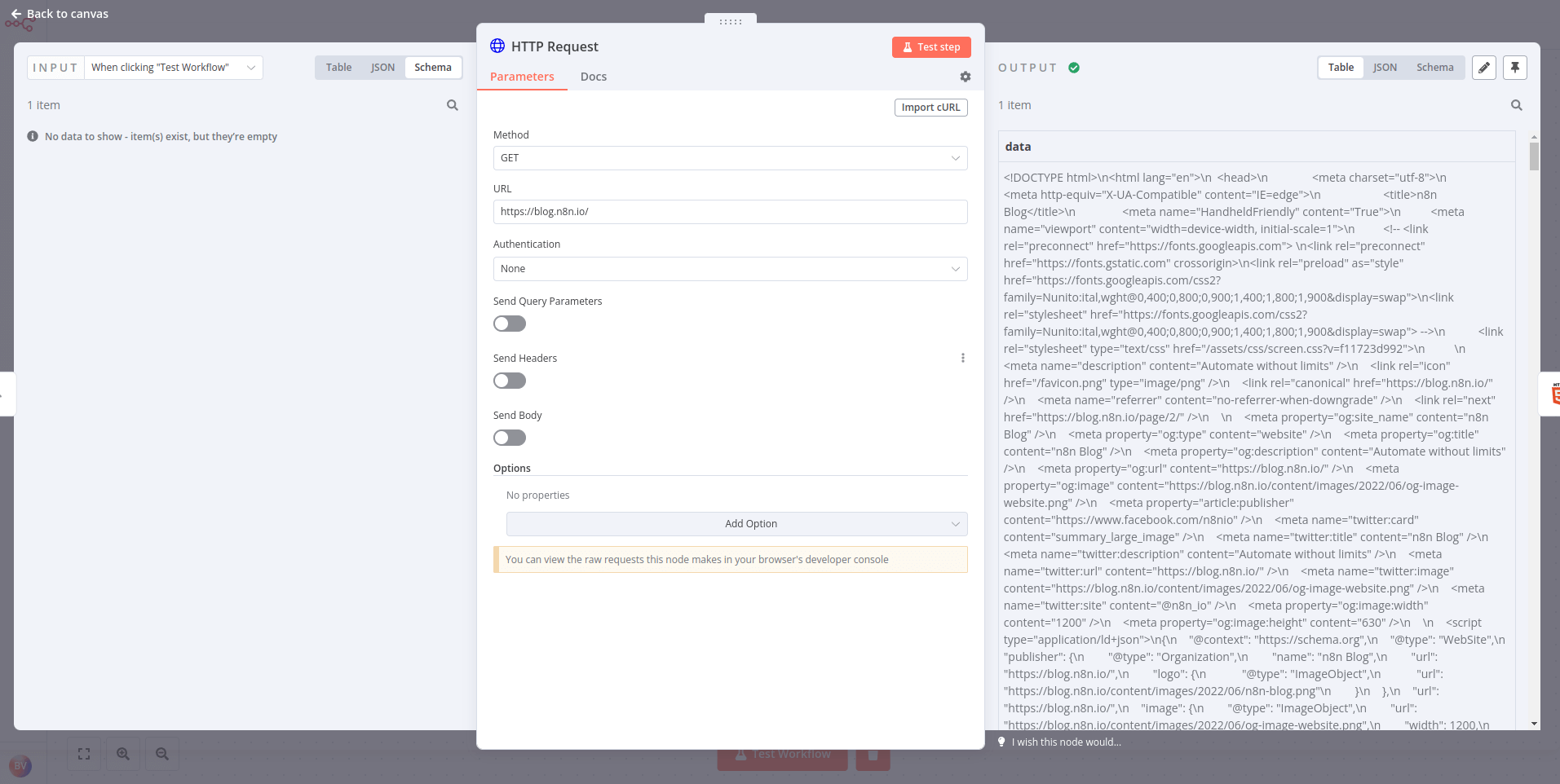
- 다음 매개변수로 HTTP Request node를 구성합니다:
- Authentication: None
- Request Method: GET
- URL: https://blog.n8n.io/ 결과는 다음과 같아야 합니다:
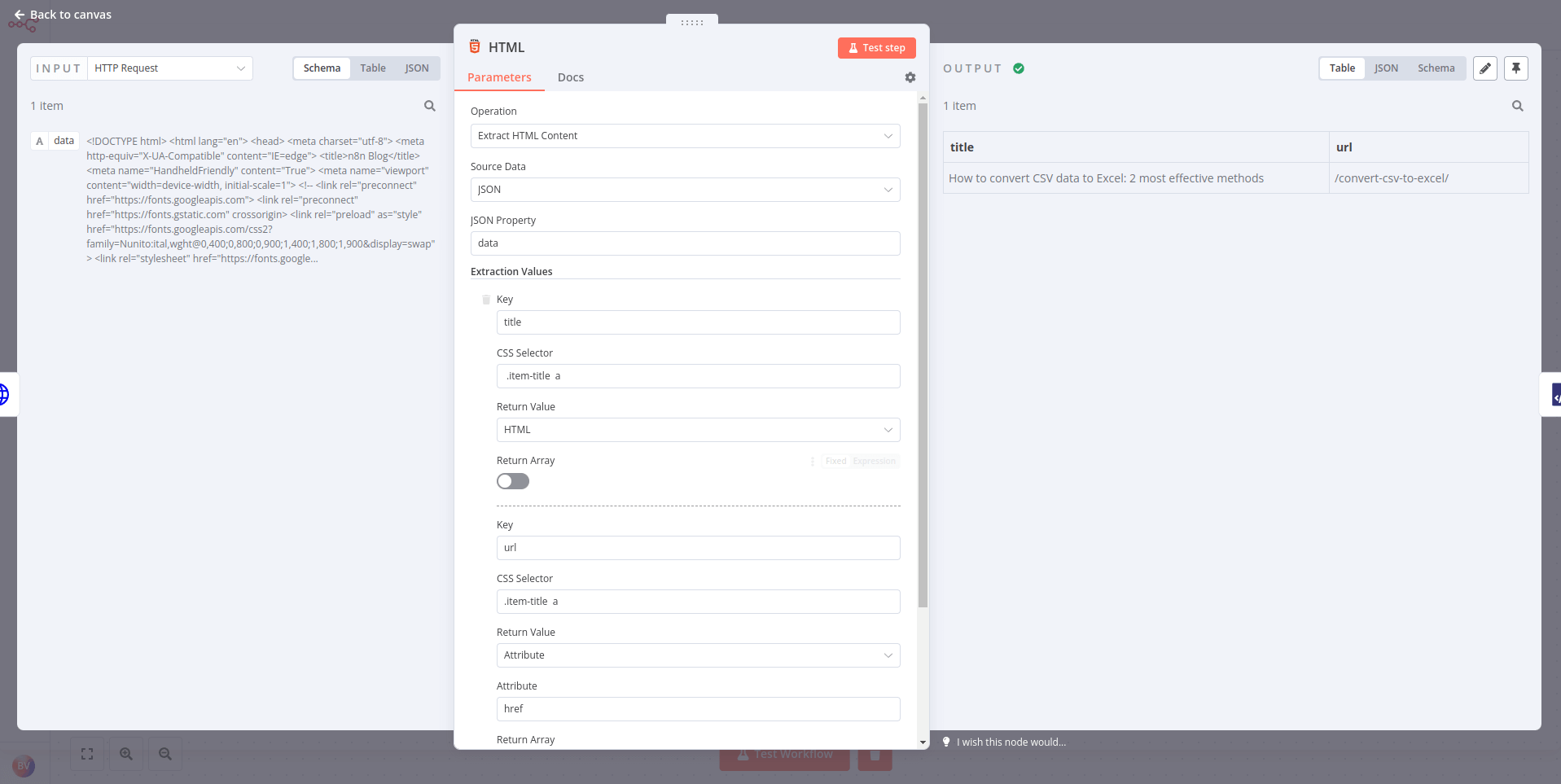
- HTTP Request node에 HTML node를 연결하고 이전 노드의 매개변수를 구성합니다:
- Operation: Extract HTML Content
- Source Data: JSON
- JSON Property: data
- Extraction Values:
- Key: title
- CSS Selector:
.item-title a - Return Value: HTML
더 많은 데이터를 추출하려면 더 많은 값을 추가할 수 있습니다.
결과는 다음과 같아야 합니다:
XML node를 사용하여 XML을 JSON으로 변환하고 JSON을 XML로 변환합니다. 이 작업은 XML 또는 JSON을 사용하는 다양한 웹 서비스와 데이터를 주고받아야 할 때 유용합니다.
XML 연습#
제 1장 마지막 연습에서 HTTP Request node를 사용하여 Quotable API에 요청을 보냈습니다. 이번 연습에서는 동일한 API에 다시 돌아가서 출력을 XML로 변환하겠습니다:
- Quotable API에
https://api.quotable.io/quotes에 동일한 요청을 하는 HTTP Request node를 추가합니다. - XML node를 사용하여 JSON 출력을 XML로 변환합니다.
해결책을 보여주세요
- Quotable API에서 인용구를 가져오려면 다음 매개변수로 HTTP Request node를 실행합니다:
- Authentication: None
- Request Method: GET
- URL: https://api.quotable.io/quotes
- 다음 매개변수로 XML node를 연결합니다:
- Mode: JSON to XML
- Property name: data
결과는 다음과 같아야 합니다:

데이터를 반대로 변환하려면 XML to JSON 모드를 선택합니다.
날짜, 시간 및 간격 데이터#
날짜 및 시간 데이터 유형에는 DATE, TIME, DATETIME, TIMESTAMP, 및 YEAR이 포함됩니다. 날짜와 시간은 다양한 형식으로 전달될 수 있습니다. 예를 들어:
DATE: 2022년 3월 29일, 29-03-2022, 2022/03/29TIME: 08:30:00, 8:30, 20:30DATETIME: 2022/03/29 08:30:00TIMESTAMP: 1616108400 (유닉스 타임스탬프), 1616108400000 (유닉스 ms 타임스탬프)YEAR: 2022, 22
날짜와 시간을 다루는 몇 가지 방법이 있습니다:
- 날짜 및 시간 데이터를 다른 형식으로 변환하고 날짜를 계산하는 Date & Time node를 사용하십시오.
- 특정 시간, 간격 또는 기간에 따라 워크플로우를 실행하도록 예약하는 Schedule Trigger node를 사용하십시오.
때때로 워크플로우 실행을 일시 중지해야 할 수도 있습니다. 이는 서비스가 데이터를 즉시 처리하지 않거나 모든 결과를 반환하는 데 느릴 경우 필요할 수 있습니다. 이러한 경우 n8n이 불완전한 데이터를 다음 노드로 전달하지 않도록 하고 싶을 것입니다.
이러한 상황에 직면하였다면 지연하고자 하는 노드 다음에 Wait node를 사용하십시오. Wait node는 워크플로우 실행을 일시 중지하고 다음과 같이 재개합니다:
- 특정 시간에.
- 지정된 시간 간격 후에.
- 웹후크 호출 시.
날짜 연습#
이전의 Customer Datastore 노드에서 입력 날짜에 5일을 추가하는 워크플로우를 작성하십시오. 그런 다음 계산된 날짜가 1959년 이후에 발생한 경우, 워크플로우는 설정하기에 1분 대기한 후 계산된 날짜를 값으로 설정해야 합니다. 워크플로우는 30분마다 트리거되어야 합니다.
시작하려면:
- 모든 사람 가져오기 작업이 선택된 Customer Datastore (n8n 교육) 노드를 추가합니다. 모든 반환.
- 데이터 스토어에서 생성된 날짜를 월말로 반올림하기 위해 Date & Time node를 추가합니다. 이것을 필드 new-date에 출력합니다. 모든 입력 필드를 포함합니다.
- 새로운 반올림된 날짜가
1960-01-01 00:00:00이후인지 확인하기 위해 If node를 추가합니다. - 해당 노드의 True 출력에 Wait node를 추가하고 1분 동안 대기하도록 설정합니다.
- Edit Fields (Set) node를 추가하여 새 필드 outputValue를 new-date를 포함하는 문자열로 설정합니다. 모든 입력 필드를 포함합니다.
- 30분마다 트리거되도록 워크플로우의 시작 부분에 Schedule Trigger node를 추가합니다. (테스트를 위해 Manual Trigger node를 유지할 수 있습니다!)
해결책을 보여줘
- Customer Datastore (n8n 교육) 노드에 모든 사람 가져오기 작업을 선택하여 추가합니다.
- Return All 옵션을 선택합니다.
- Customer Datastore 노드에 연결된 Date & Time node를 추가합니다. 날짜 반올림 옵션을 선택합니다.
- 반올림할 날짜로
created날짜를 추가합니다. - 모드로
Round Up을 선택하고 To로End of Month를 선택합니다. - Output Field Name을
new-date로 설정합니다. - Options에서 Add Option을 선택하고 입력 필드를 포함할 수 있도록 제어를 사용합니다.
- 반올림할 날짜로
- Date & Time node에 연결된 If node를 추가합니다.
- 조건의 첫 번째 부분으로 new-date 필드를 추가합니다.
- 비교를 Date &Time > 이 후로 설정합니다.
- 표현식의 두 번째 부분으로
1960-01-01 00:00:00을 추가합니다. (이것은 True 분기에서 3개 품목과 False 분기에서 2개 품목을 생성해야 합니다.)
- If node의 True 출력에 Wait node를 추가합니다.
- Resume를
After Time interval로 설정합니다. - Wait Amount를
1.00으로 설정합니다. - Wait Unit을
Minutes로 설정합니다.
- Resume를
- Wait node에 Edit Fields (Set) node를 추가합니다.
- JSON 또는 수동 매핑 모드 중 하나를 사용합니다.
- 새 필드 called
outputValue를 new-date 필드의 값으로 설정합니다. - 기타 입력 필드를 포함하고 모든 필드를 포함하도록 선택합니다.
- 워크플로우 시작 부분에 Schedule Trigger node를 추가합니다.
- Trigger Interval을
Minutes로 설정합니다. - Minutes Between Triggers를 30으로 설정합니다.
- 스케줄을 테스트하려면 워크플로우를 활성화합니다.
- 시작했던 Customer Datastore (n8n 교육) 노드에 이 노드를 연결하도록 하세요!
- Trigger Interval을
워크플로우는 다음과 같아야 합니다:
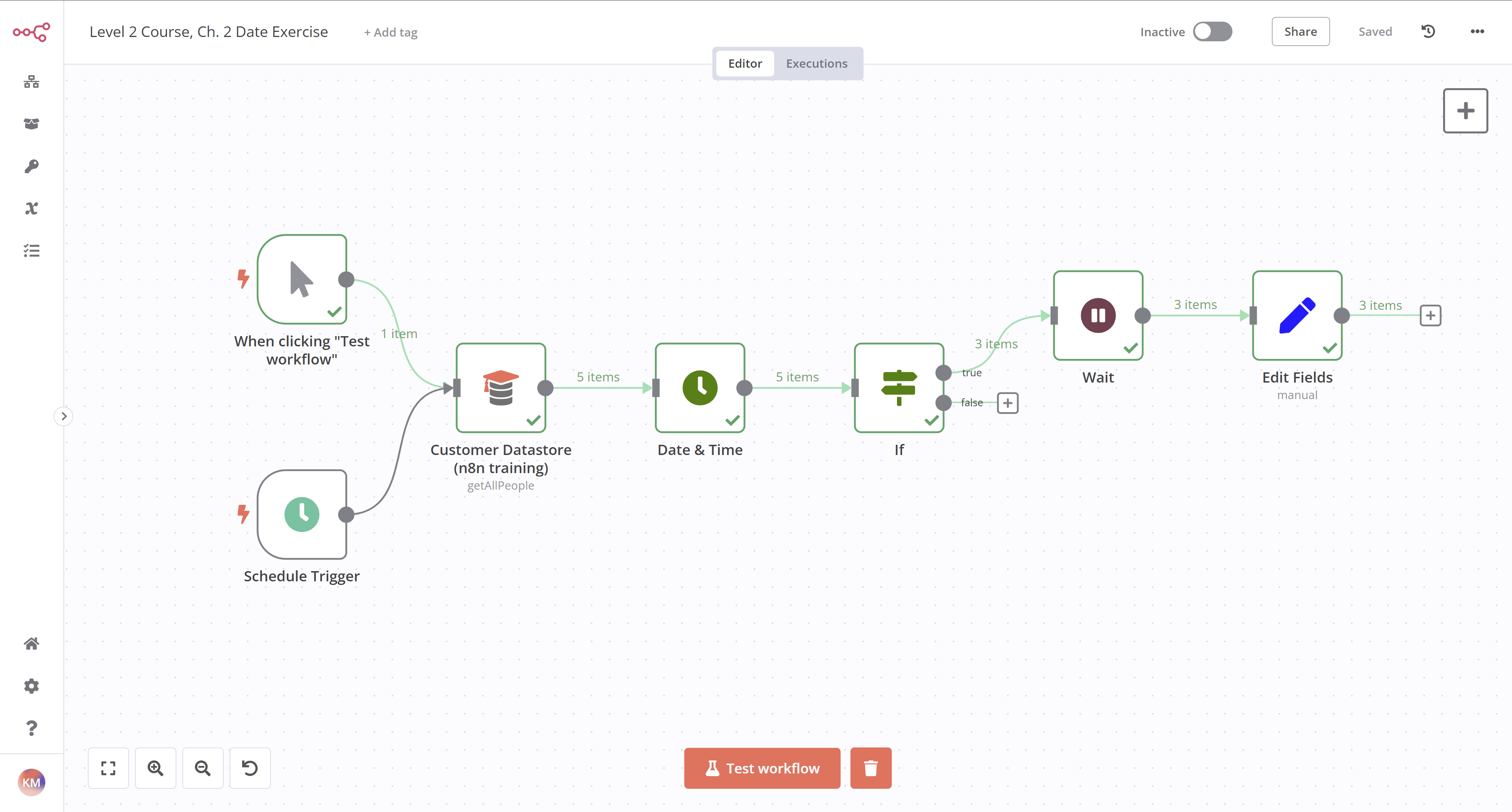
각 노드의 구성을 확인하려면 이 워크플로우의 JSON 코드를 복사하여 Editor UI에 붙여넣거나 파일로 저장하고 새 워크플로우로 가져오십시오. 자세한 내용은 워크플로우 내보내기 및 가져오기를 참조하세요.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 | |
이진 데이터#
지금까지 주로 텍스트 데이터와 작업해왔습니다. 하지만 텍스트가 아닌 데이터, 예를 들어 이미지나 PDF 파일을 처리하고 싶다면 어떻게 할까요? 이러한 유형의 파일은 이진 숫자 시스템으로 표현되므로 이진 데이터로 간주됩니다. 이 형태로는 이진 데이터가 유용한 정보를 제공하지 않으므로, 읽을 수 있는 형태로 변환해야 합니다.
n8n에서는 다음 노드를 사용하여 이진 데이터를 처리할 수 있습니다:
- HTTP Request 노드를 사용하여 웹 리소스 및 API에서 파일을 요청하고 전송합니다.
- Read/Write Files from Disk 노드를 사용하여 n8n이 실행되고 있는 머신에서 파일을 읽고 씁니다.
- Convert to File 노드를 사용하여 입력 데이터를 파일로 출력합니다.
- Extract From File 노드를 사용하여 이진 형식에서 데이터를 가져오고 JSON으로 변환합니다.
파일 읽기 및 쓰기
파일을 디스크에 읽고 쓰는 기능은 자가 호스팅 n8n에서만 사용할 수 있습니다. n8n Cloud에서는 파일을 읽고 쓸 수 없습니다. n8n을 설치한 머신에서 읽고 쓰게 됩니다. n8n을 Docker에서 실행하는 경우, 명령은 Docker 호스트가 아닌 n8n 컨테이너에서 실행됩니다. Read/Write Files From Disk 노드는 n8n 설치 경로를 기준으로 파일을 찾습니다. n8n은 오류를 방지하기 위해 절대 파일 경로를 사용하는 것을 권장합니다.
이진 파일을 읽거나 쓰려면 노드의 File(s) Selector 매개변수(읽기 작업용) 또는 노드의 File Path and Name 매개변수(쓰기 작업용)에 파일의 경로(위치)를 입력해야 합니다.
올바른 경로 명명
파일 경로는 n8n을 실행하는 방식에 따라 약간 다르게 보입니다:
- npm:
~/my_file.json - n8n cloud / Docker:
/tmp/my_file.json
이진 연습 1#
첫 번째 이진 연습으로, PDF 파일을 JSON으로 변환해봅시다:
- 이 PDF 파일을 가져오기 위해 HTTP 요청을 만듭니다:
https://media.kaspersky.com/pdf/Kaspersky_Lab_Whitepaper_Anti_blocker.pdf. - Extract From File 노드를 사용하여 파일을 이진에서 JSON으로 변환합니다.
해결책을 보여줘
HTTP Request 노드에서, PDF 파일이 다음과 같이 표시됩니다:
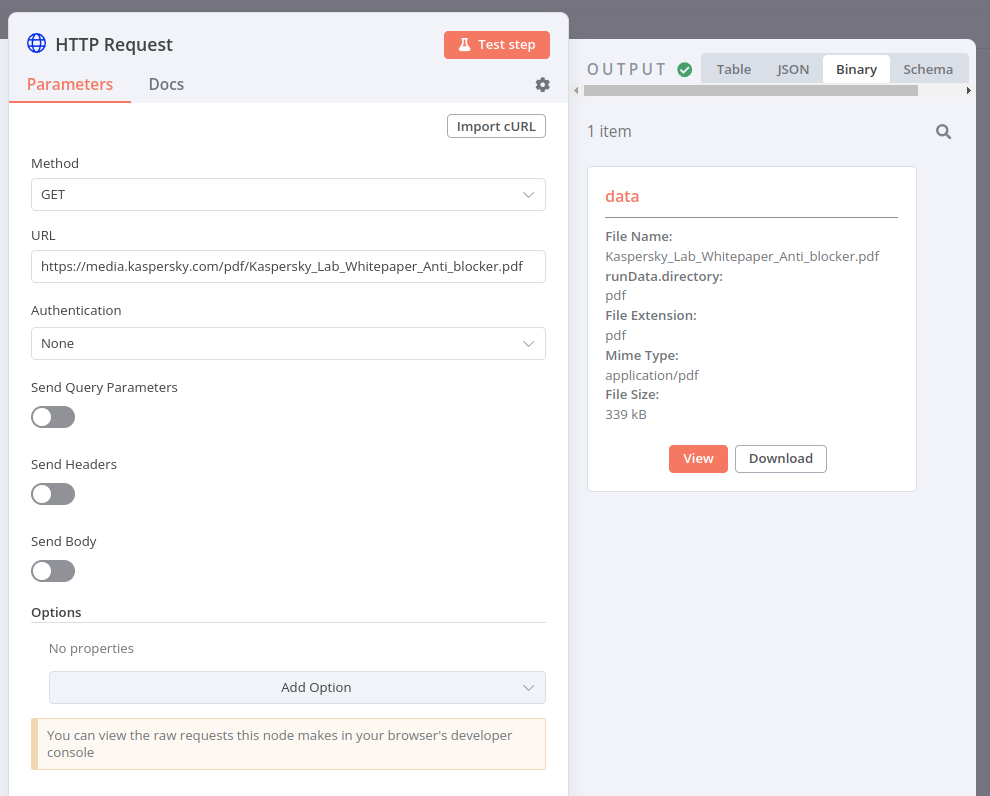
Extract From File 노드를 사용하여 이진에서 JSON으로 PDF를 변환하면 결과는 다음과 같아야 합니다:
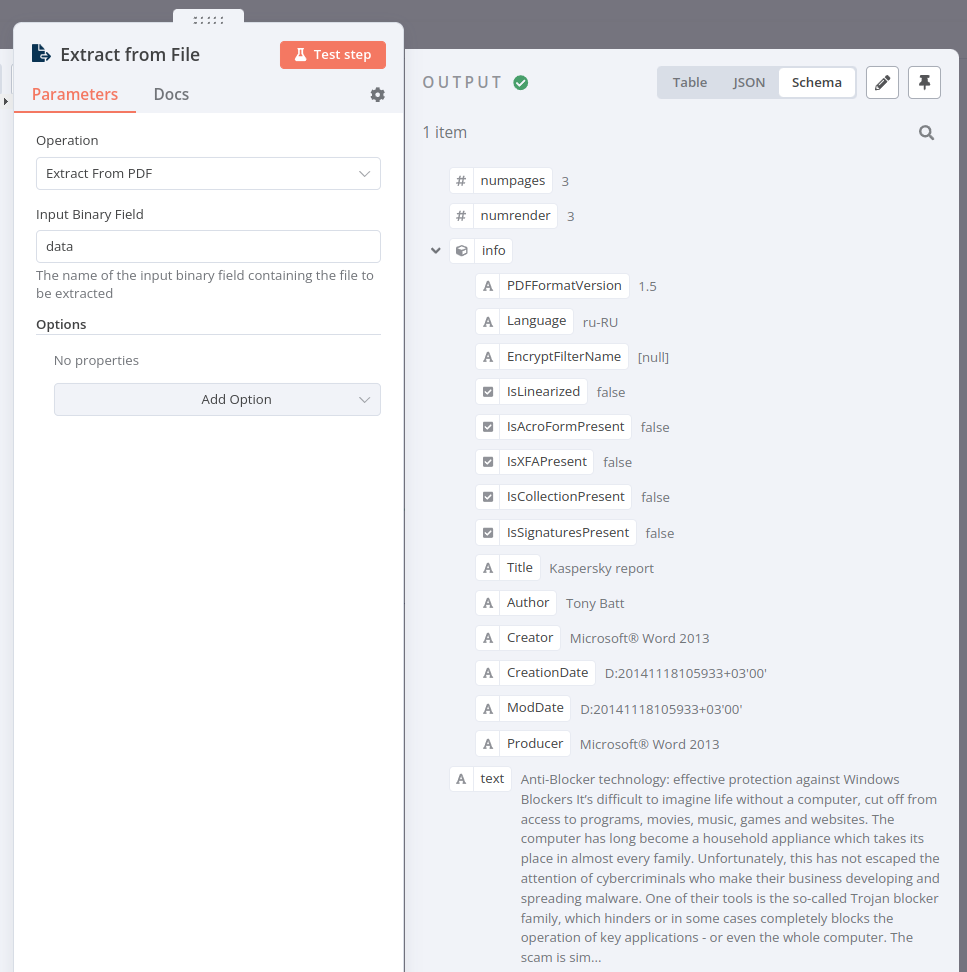
노드의 구성을 확인하려면 아래의 JSON 작업 코드 복사하여 에디터 UI에 붙여넣을 수 있습니다:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 | |
이진 연습 2#
두 번째 이진 연습으로, 일부 JSON 데이터를 이진 데이터로 변환해 보겠습니다:
- Poetry DB API에 HTTP 요청을 합니다
https://poetrydb.org/random/1. - 반환된 데이터를 JSON에서 이진으로 변환합니다 Convert to File node를 사용하여.
- 새로운 이진 파일 데이터를 n8n이 실행되고 있는 기계에 저장합니다 Read/Write Files From Disk node를 사용하여.
- 성공적으로 작업되었는지 확인하기 위해 Read/Write Files From Disk node를 사용하여 생성된 이진 파일을 읽습니다.
해결책을 보여줘
이 연습을 위한 워크플로우는 다음과 같습니다:
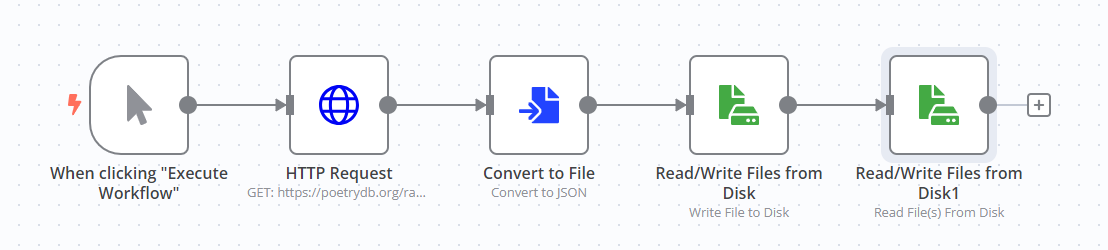
노드의 구성을 확인하려면 아래의 JSON 워크플로우 코드를 복사하여 에디터 UI에 붙여넣기 하시면 됩니다:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 | |